Today's Internet has changed quite a bit from the Internet I used to know. The Internet has always been successful because of net neutrality. What's net neutrality? It's complicated, but essentially it means that anyone anywhere can publish with equal rights. These aren't the kind of rights people usually talk about… I'm not speaking of freedom of speech. Instead, I'm talking about content being simply bits. It doesn't matter if it comes from CNN or my personal blog, you as a reader can download the bits that make up the pages you see without bias or preferential treatment. This makes it darn easy to be a publisher and leads to a fabulous ecosystem with an overwhelming amount of varied content. However, with more content it is easy to recognize that much of it is utter trash. Yes. Yes. I know that one man's trash is another man's treasure. However, it presents opportunities for sites that help you navigate the wasteland.
Many popular sites today are popular because they link to articles and news items and photographs and movies all over the Internet; they are "interest aggregation services." And while the Internet has (for now) a decent preservation of net neutrality when it comes to simple web content, not all publishers are on equal footing. Not long ago, anyone could run a server anywhere (their basement) with DSL or cable or (gasp) dial-up -- now, the challenge is coping with unexpected attention.
Years ago, the site slashdot coined a term "slashdotted" which meant that a site received so much sudden traffic that service degraded beyond an acceptable point and the site was effectively unavailable. This often happened to sites that were at the end of small pipes (DSL, T1, etc.) and occasionally (though rarely) due to bad engineering. While slashdot might have coined the term, they simply don't have the viewership numbers that other large sites today have.
At OmniTI, I work on sites that aren't on the end of T1 lines. Sites with gigabits or tens of gigabits of connectivity. Sites with 50 million or more users. Sites powered by thousands of machines. I also work on sites that service millions of people from just a handful of machines (efficiency certainly has its advantages sometimes). I find it particularly interesting that already popular sites (with significant baseline bandwidth) are seeing these unexpected surges. For a long time, my blog has been on this same machine which is a vhost for several other web sites. I've had traffic spikes from places like slashdot, reddit, digg, etc. And, no surprise, I couldn't actually see the bandwidth jump on the graphs… 10Mbits to 11Mbs? That's not a spike.
Things are changing. Sites like Digg are becoming ever more popular and people are drawn to them as a means of sifting the waste of the Internet. This means as more people rely on Digg and Reddit and other similar sites, the number of unexpected viewers of your content can rise more sharply.
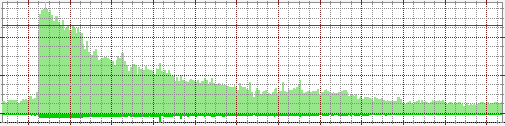
What does all of this mean? It means that the old rule of thumb that your infrastructure should see 70% resource utilization at peak is starting to falter. The typical trends used to look like this (this is last week's graph from a retail client with a user base of 3 million):
We see a nice peak, a nice valley. Thursday afternoon, we see a nice traffic spike. Well, this used to be what I called a traffic spike. Now, different services have different spike signatures. It resembles traffic model of classic Internet advertising, except that there is genuine interest and thus dramatically higher conversion rates. It's a simple combination of placement, frequency and exposure. Because content, unlike ad banners, exists for an extended period of time (sometimes forever), the frequency is very high. Digg and Reddit have excellent placement with very little exposure (things move out quickly). A site like CNN or NYTimes usually provides mediocre placement (unless you are on the front page) and excellent exposure.
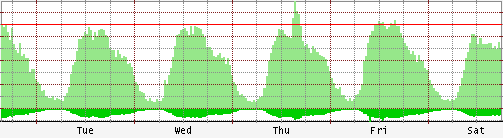
Lately, I see more sudden eyeballs and what used to be an established trend seems to fall into a more chaotic pattern that is the aggregate of different spike signatures around a smooth curve. This graph is from two consecutive days where we have a beautiful comparison of a relatively uneventful day followed by long-exposure spike (nytimes.com) compounded by a short-exposure spike (digg.com):
The disturbing part is that this occurs even on larger sites now due to the sheer magnitude of eyeballs looking at today's already popular sites. Long story short, this makes planning a real bitch.
And the interesting thing is perspective on what is large… People think Digg is popular -- it is. The New York Times is too, as is CNN and most other major news networks -- if they link to your site, you can expect to see a dramatic and very sudden increase in traffic. And this is just in the United States (and some other English speaking countries)… there are others… and they're kinda big.
What isn't entirely obvious in the above graphs? These spikes happen inside 60 seconds. The idea of provisioning more servers (virtual or not) is unrealistic. Even in a cloud computing system, getting new system images up and integrated in 60 seconds is pushing the envelope and that would assume a zero second response time. This means it is about time to adjust what our systems architecture should support. The old rule of 70% utilization accommodating an unexpected 40% increase in traffic is unraveling. At least eight times in the past month, we've experienced from 100% to 1000% sudden increases in traffic across many of our clients.
I talk about scalability a lot. It's my job. It's my passion. I regularly emphasize that scalability and performance are truly different beasts. One key to scalability is that a "systems design" scales. Architectures are built to be able to scale, they are not built "at scale." It's just too expensive to build a system to serve a billion people (until you have a billion people). It's cheap to design a system to serve a billion people. Once you have a billion people accessing your site, you can likely justify executing on your design. Google is successful for this reason: their ideas scale and they can build into them as demand rises. On the flip side, traffic anomalies in the form of spikes are unexpected (by their definition) and scaling a system out to meet the unexpected demand is almost unreasonable. I would even argue that it is more of a performance-centric issue. I want every asset I serve to be as cheap to serve as possible allowing me to handle larger and larger spikes.
The reason I find all of this stuff interesting is that understanding performance and scalability, understanding the principles of scalable systems design and having sound and efficient processes for handling performance issues is becoming crucial for sites regardless of their size. This takes insight and practice and it reminds me of Knuth's famous saying:
We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil.
That's all well and good, but which 97% of the time? My response to Knuth's statement (with which I completely agree) is:
Understanding what is and isn't "premature" is what separates senior engineers from junior engineers.
Let's add perspective on the word "sudden." Most network monitoring systems poll SNMP devices (like switches, load-balancers, and hosts) once every five minutes (we do this every 30 seconds in some environments). Some people say, "my site scales! bring it on." We see these spikes happen inside 60 seconds and they occasionally induce a ten-fold increase over trended peaks. Often times, this spike can be well underway for several minutes before your graphing tools even pick up on it. Then, before you have time to analyze, diagnose and remediate… poof… it's gone. Be careful what you wish for.
This, in many ways, is like a tornado. Our ability to predict them sucks. Our responses are crude and they are quite damaging. However, predicting these Internet traffic events isn't even possible -- there are no building weather patterns or early warning signs. Instead we are forced to focus on different techniques for stability and safety. The idea of a DoS, a DDoS or the sometimes similar signature of a sudden popularity spike doesn't increase my heart rate anymore -- it's just another day on the job. However, I thought I'd share the four guidelines that I believe are key to my sanity in these situations:
- Be Alert: build automated systems to detect and pinpoint the cause of these issues quickly (in less than 60 seconds).
- Be Prepared: understand the bottlenecks of your service systemically. Understanding your site inside and out. Contemplate how you would respond if a specific feature or set of features on your site were to get "suddenly popular."
- Perform Triage: understand the importance of the various services that make up your site. If you find yourself in a position to sacrifice one part to ensure continued service of another, you should already know their relative importance and not hesitate in the decision.
- Be Calm: any action that is not analytically driven is a waste of time and energy. Be quick, not rash.
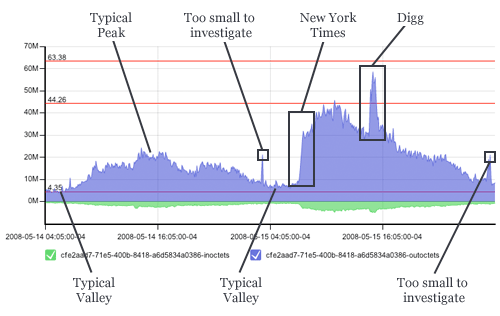
Back to those other countries… Enter China and their recently lessened censorship and we have a looming tidal wave for smaller sites that achieve sudden popularity. Spikes of several hundred megabits per second are difficult to account for when your normal trend is around twenty megabits per second. The following graph is traffic induced from a link from a popular foreign news site (that I can't read). I call it: "ouch:"