I recently attended the O'Reilly Velocity 2010 conference in Santa Clara, CA. For the past two years this conference attracted some of the smartest minds in web performance and web operations; this year did not disappoint.

~ James Duncan Davidson (original)
Several exciting things debuted including Opscode's hosted platform, Yahoo!'s Boomerang and our very own Circonus Enterprise Platform.
Each year, the conference has adopted the mantra: "fast by default." This statement, largely applying to the web operations track, is an excellent theme. The concept is that speed is feature number one and that your success as a online company is intrinsically tied to how users perceive the performance of your online presence. This is true, the numbers tell us so.
The interesting part about web performance is that user-perceived performance comes from three separate elements: computation done by the service, computation done by the user and act of getting data between the two. Velocity really focuses on the latter two: how do I optimize how content is delivered to my users and optimize how it performs once they've got it? This perspective is incomplete. Should Velocity change to address all three elements? I say no. The audiences are different, the problems are different and there is no need to mess with a good thing. Surge, on the other hand, only concentrates on the first element: server side performance and scalability.
Let's face it, the server-side architectures that power today's web services are as unique as the services they power. Each site has its own unique challenges that come with its size, technologies, audience, offering and promises. Not to trivialize the web performance challenge, but the techniques used to increased user-perceived importance in transit and on the client side are largely the same from site to site (clean, small and effective DOM, CSS and Javascript, correct caching, image sprites, HTTP compression, etc.). However, on the server side is where the unique magic happens.
Do you really think that the technology powering Google's new Caffeine search indexer could be leveraged easily to help your internal service delivery platform? No. For a user to use your service, in an over-simplified form, they provide some input and receive from output. Each time they ask a question and expect a result, you must "do some work." Herein lies the challenge.
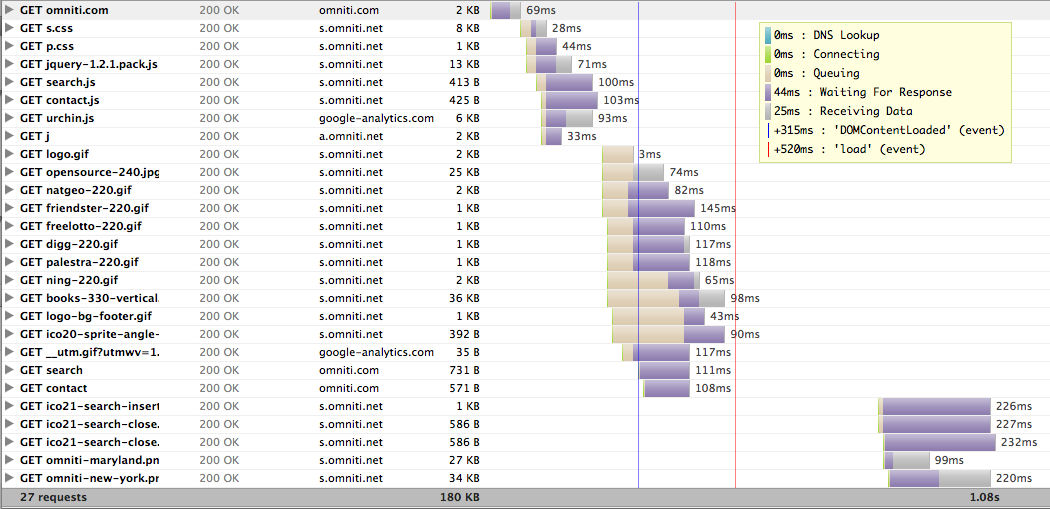
In a previous installment "YSlow to YFast in 45 Minutes", I explored reaping low-hanging fruit to achieve user-perceived speed-ups on this very site. The main effort there was to shorten the event horizon to render by removing, shortening and/or parallelizing various assets on which a page depends. The obvious, but often ignored, part is that it all starts with a single request: "the page."
On the OmniTI web site, there is very little going on and as such, you'd expect that very little time is spent on our end "doing work" to give you the page content. If you look at the details, you can see that to be true: 44 milliseconds waiting for data to start and 25 additional milliseconds waiting for the data to come down the pipe. This is relatively fast. This is not always the case; in fact, it often is not the case.
I was quite interested in this division of time and asked my helpful friends at Keynote for some aggregate information. That information paints a rather interesting picture. The average speed of a "web page load" comes in at over 2 seconds. Obviously, these 2 seconds are split in some fashion amongst our three buckets. What may be quite surprising is that, on average, 290ms seconds is spent server-side. I speculate this is due to one of two reasons. Most commonly, it is due to a lack of attention to how the architecture internally operates resulting in sloppy code and data architecture. To me, this is the better of the two reasons. The other reason is a focus on "scale-out" with a blatant disregard for a maximum acceptable service time.
One web performance company, who shall remain nameless, actually spends as much as 2 seconds "thinking" before sending data to the client, producing an awful waterfall. Note that the client-side performance is quite excellent, but still the user waits uncomfortably long.

To put this in some perspective, a processor today can operate around 2.9GHz (that's 2.9 billion instructions per second). 290ms sans a conservative 90ms of round-trip latency is 200ms of operating time or 580 million CPU instructions. The disturbing part of this is that most of what Keynote monitors is landing pages or specific hot paths, so many other pages on these websites are slower. We all know that most websites today are more complicated than a single machine serving information, so a direct correlation of service time to CPU cycles is deeply flawed; however, I still believe it is illustrative, useful and compelling.
Furthermore, if your system is spending 200ms servicing a single request, you can do the simple math to find that even on an 8-way system, you can still only serve 40 requests/second. As your demand increases, you must add more and more machines. While provisioning these machines used to be challenging, the cloud has played on general performance-optimization delinquency and made this approach seem acceptable by making massive machine provisioning easy. I'm here to tell you it is not acceptable. Not only is it environmentally wasteful (using power and generating unnecessary heat), it is also wasteful of shareholder investment. Faster sites running more optimally generate shareholder value.
The pervasive focus on front-end performance is explained by the easy gains that can be seen from relatively little investment. However, as the numbers show, for most sites this simply isn't enough to compete. Shopzilla recently completed a 12 month engineering effort to rearchitect their application because the server-side was too slow (pushing 8 seconds). Now that it is blazingly fast, they have less infrastructure to maintain per dollar of revenue and an increase in revenue of 7-12%.
Attention to internal performance in fundamental to the success of online businesses. Many of the larger web-based companies have smart people on staff that take performance seriously. If you need help, this is what we work on for our clients everyday at OmniTI.
{kind=link}