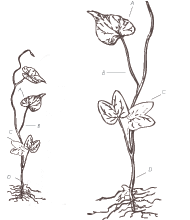
One of the important differences about OmniTI is that we don't just build software for people, we actively manage high traffic web infrastructure. This means that, as developers, we live with the technical debt that we build, and we use our best judgment to help pay off that debt when it makes sense. Recently, we were reviewing our monitoring graphs and took some time to look at our memcached instances. This particular client uses Circonus and has metrics set up for memcache including total memory, fetch/put rates (both requests and bytes), and hit/miss rates.
These misses aren't particularly large in volume, however cache misses are often a sign that something in the system could be faster. They can be worth investigating before traffic scales up and small inefficiencies begin to add up.
Diagnosing
We know there are misses happening, but we have cache calls all over the code. To track this down, we need to see what is really happening on the system in order to observe what is being missed. Unfortunately, memcached provides no internal mechanism for doing this, making this a difficult enough task that some people have written 3rd party applications specific for doing it, such as mctop. Luckily for me, these systems are running on Illumos so we have the benefit of the dtrace utility. Dtrace allows me to inspect production systems in detail with virtually no risk, so we can look directly at one of the memcache instances and see what is happening in real-time. Rather than writing our own, we used a great memcached dtrace script by Matt Ingenthron that he kindly makes available at https://gist.github.com/ingenthr/6116473
Running the keyflow script on one of the production machines we see keys as they are being fetched or set.
$ sudo ~/memcache_scripts/keyflow.d
get OGefRqwX:45220, FOUND KEY
get H02pZPjq:2087rulessml::en, FOUND KEY
get 3P4iT8M/:4, FOUND KEY
get WETtYDA0:__special_reg_map, FOUND KEY
get WETtYDA0:__special_reg_map, FOUND KEY
get 3P4iT8M/:4, FOUND KEY
get suB5w6XF:683112, FOUND KEY
get 3P4iT8M/:4, FOUND KEY
get WETtYDA0:1:default, FOUND KEY
get WETtYDA0:1:default, FOUND KEY
get H02pZPjq:2087rulessml::en, FOUND KEY
get 3P4iT8M/:4, FOUND KEY
...
What's showing are the memcache commands and keys; 'get' saying, 'fetch this from memcached', the key it is attempting to fetch, and the result. This client's internal caching code uses a wrapper module to namespace keys based on their module (the first 9 characters), and then a developer supplied key.
We really only care about the misses, so let's filter for just those:
$ sudo ~/memcache_scripts/keyflow.d | grep NOT
get WETtYDA0:1:Win-A-Mercedes-Benz, NOT FOUND
get OGefRqwX:98801, NOT FOUND
get OGefRqwX:78634, NOT FOUND
...
Watching this for a bit, we noticed a few commonalities on cache misses. We picked a key that seemed to be showing up with high frequency (“rest_api:gmail.com”) and started from there.
Bugs Aren't Always Your Fault
This key had a namespace, so we can start by looking at the key flow happening by grepping for that namespace.
$ sudo ~/memcache_scripts/keyflow.d | grep rest_api
get rest_api:hotmail.com, NOT FOUND
get rest_api:gmail.com, NOT FOUND
get rest_api:gmail.com, NOT FOUND
get rest_api:gmail.com, NOT FOUND
get rest_api:gmail.com, NOT FOUND
get rest_api:yahoo.com, NOT FOUND
get rest_api:gmail.com, NOT FOUND
get rest_api:gmail.com, NOT FOUND
get rest_api:gmail.com, NOT FOUND
get rest_api:gmail.com, NOT FOUND
get rest_api:gmail.com, NOT FOUND
get rest_api:gmail.com, NOT FOUND
get rest_api:gmail.com, NOT FOUND
The customer's Node.js REST API was making memcache fetch calls with the same domain repeatedly. A common pattern after a cache miss is to make a request to an authoritative source and then set that value in the cache for next time. In this case, we don't see any sets, only fetches for the same item repeatedly. Time to dig in.
We were able to quickly identify where the cache call was being made. This customer rejects registrations through the API for domains that are members of their blacklist. The list is very large so we only want to cache the current ‘hot’ domains and fall back to a database check for the rest. The code for this was pretty simple.
// Try to find the domain in the cache
mc.get(key, function(err, data){
if(err || “undefined” === typeof data){
// Hit the database if nothing was found
return queryIllegalDomainEmail( email.domain, function(err, res){
if(err){
return callback(err);
}
// Cache what we got from the db
mc.set(key, res, 3600);
return callback(null, res);
});
} else {
return callback(null, data);
}
});
If the key is not in cache, query for it, set it, and then keep going. The code ignores return values from set() since if there is an error we aren't really going to do anything about it. To debug the issue, we add a callback to set to see what the response is. Strangely, at this point, it started working! We could see "set" commands going to memcached from the dtrace script. Digging deeper into the set() function call, we find this is actually an issue with the npm module that we are using to handle memcached. If a callback is not provided to the set() function, the module’s validation module does not see it as a function and believes there is a type mis-match. It then tries to return an error using the provided callback, which doesn't exist, so it does nothing; failing silently. This is a horrible failure case. If a callback function is required, it should fail loudly and immediately. If it is not required, then it should continue to work as expected; provided nothing was wrong with the request. The entire rest of the package code is written to work correctly if no callback is provided, so changing the validation function in the npm module source code to allow undefined callbacks is all that was needed.
We created an issue in the module’s github repo, and submitted a pull request with a test case to the project. We'll see if they agree.
Caching For Negative Responses
The next largest cause of cache misses was a common error. When checking cache, we often say, "what is the value of X?" If we don't find it, we will check the authoritative source. But what if the authoritative source also doesn't have it? Often times, we just move on. Take, for example, a tracking code sent to a purchase page. Certain codes automatically give someone a discount of 10% so we need to check if it's a special code. If it's not, then we don't do anything. This was one of those cases. However, overwhelmingly, the majority of these lookups return nothing as they were only used for tracking. ‘Nothing’ is also a value and may be cached. By caching the negative response or lack of a value the page can continue to avoid the slow database lookup. This improves page load time in the common case. It is important to keep your business rules in mind for invalidation of this data. If a discount is added how long will it take for your cache values to expire to reflect the new value?
Don't Refetch Things You Already Know
The next item is a bit harder to diagnose. While watching some of the access patterns, we noticed that the same key would often be fetched several times in a row. Curious why this was such a heavily requested key we investigated it as well.
There are plenty of things people hate about Object Oriented Programming but a particular pet peeve is that the 'black box' approach often hides how expensive particular calls can be. This customer has several different views that can be displayed for a page depending on context, and often times different behaviors are turned on/off based on that particular view. These flags would be provided by creating a Page object and checking it. e.g.:
my $page = new PageObject( $request );
if( $page->do_the_thing() ) {
// Do the thing.
}
As features were added/removed, these calls ended up sprinkled all over the code wherever a flag had to be checked. Unknown to the programmer, this constructor is fetching those flags from memcache. After months of new feature requests, the code would now fetch that same data from memcache 7-10 times on a single page load. With a bit of refactoring this is easily avoided by fetching the data once at the start, and passing the object to the various and sundry logic paths that followed. Memcache calls in our network are only a few milliseconds, but these milliseconds add up.
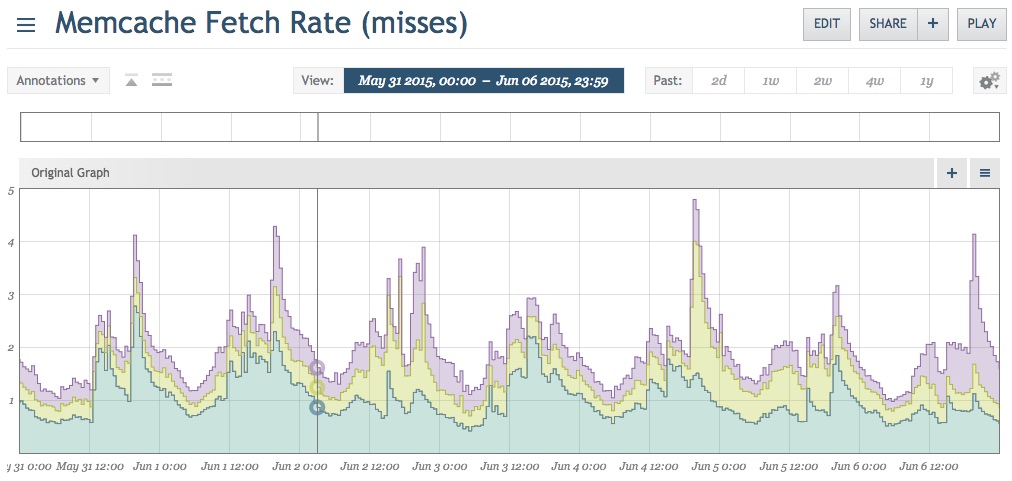
Results
This graph is comprised of the two days before and after the fix. Miss rates are down to almost nothing:
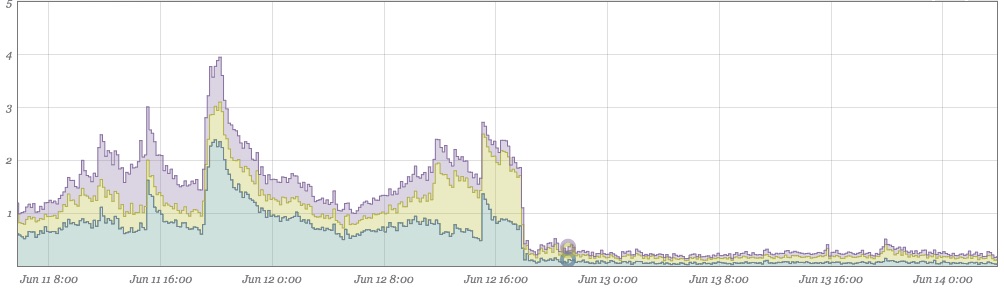
Just as welcome (below), cache hit volume is now also down due to no longer fetching the same value multiple times on the same page load. On the below graph, the left side is the new traffic pattern overlaid with the previous week. After the push, we see roughly a 10%- 20% drop in the total number of memcached fetches. All of that is time saved getting the pages out to customers faster.
Removing Noise Makes Events Stand Out More
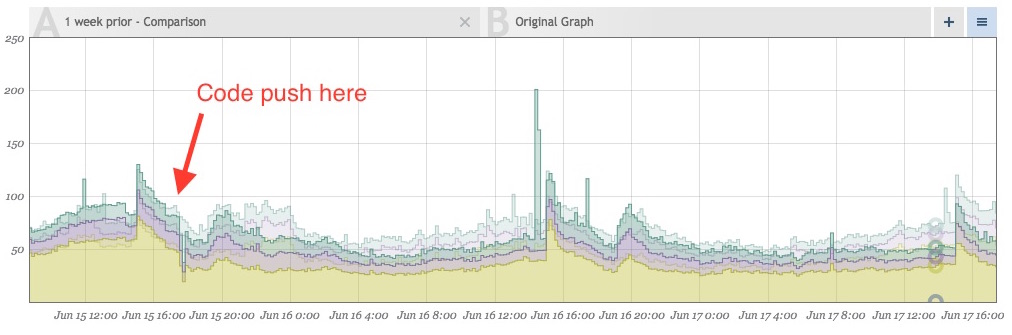
After cleaning our data up, the lack of noise makes events that stray from the norm even more visually apparent. Shortly after implementing the above fixes, this jumped out at us:
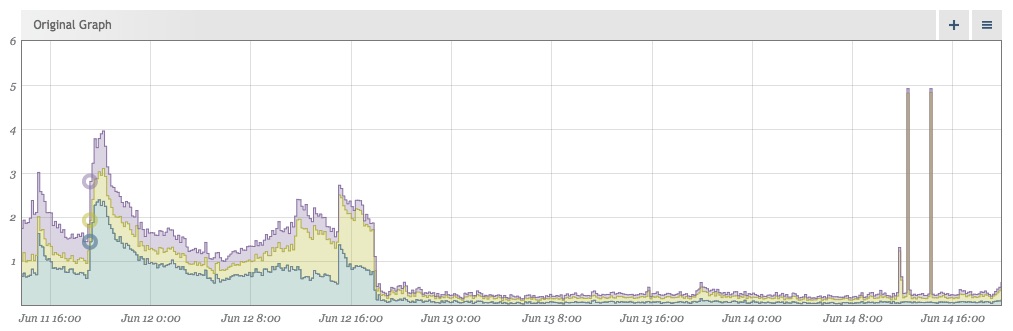
Make Sure Your Own Libraries Are Correct
While we were able to look at real-time traffic for our previous issue, investigating these spikes had to be done after the fact, but we still needed to find out what was happening just the same. Grabbing some of the traffic logs from that time, we were able to replay some traffic and find the culprit. It was pretty concerning.
get WETtYDA0:1:999999.9', NOT FOUND
get union, NOT FOUND
get all, NOT FOUND
get WETtYDA0:1:CertifiedWinnerRSP, FOUND KEY
get WETtYDA0:1:default, FOUND KEY
get WETtYDA0:1:999999.9', NOT FOUND
get union, NOT FOUND
get all, NOT FOUND
get WETtYDA0:1:CertifiedWinnerRSP, FOUND KEY
get WETtYDA0:1:default, FOUND KEY
get WETtYDA0:1:999999.9', NOT FOUND
get union, NOT FOUND
get all, NOT FOUND
get WETtYDA0:1:CertifiedWinnerRSP, FOUND KEY
get WETtYDA0:1:default, FOUND KEY
It looks like we were trying to pull snippets of SQL queries from memcache. Sure enough, log investigation shows the site was being scanned at that point. An SQL injection attempt was causing the extra cache key fetches.
We could reproduce the error by hitting one of our dev machines with the following:
https://dev.site.com/page?type=999999.9%27%20union%20all%20
This translates to a type value of:
“999999.9' union all”
The same three keys we were trying to fetch.
This turned out to be a bug with the internal wrapper module. The module would just accept whatever key it was given and attempt to fetch it. This does not play nicely with the memcache protocol. A memcache key may not contain any whitespace or control characters, and must be <= 250 characters. Whitespace in the get request are used to allow someone to fetch multiple keys with a single fetch command, which is what we were doing and the reason why dtrace showed it as three separate fetches. Since our module would just take the first response and ignore the rest, there was no vulnerability here (yay!), just inefficiencies. Doing multiple gets at once is a great technique to combine requests, but the context of this module is assuming a single key get request.
To fix it, the module was modified to strip invalid values out. The example would now attempt to fetch:
'WETtYDA0:1:999999.9unionall'
This would be a single fetch attempt, cache miss, and life would go on.
Conclusions
1. Caching is a great tool, but like all parts of a system, it's worth revisiting things now and again to make sure things are working the way they should be. It may be possible to find some cheap performance gains and some good examples of anti-patterns.
2. There's a lot of benefits to monitoring beyond just looking for errors. None of these bugs were particularly bad, in fact, most of them still produced the correct outcome. Monitoring isn't always to show where mistakes are, but where improvements can be made, and just as importantly to show if they were successful or not.